Benchmarking Neural Networks
Methods for calculating the performance of the neural network models



FLOPS
- Floating Point Operations per Second
- The higher number of operations per second, the faster inference for the model
| Name | Unit | Value |
|---|---|---|
| kiloFLOPS | kFLOPS | 10^3 |
| megaFLOPS | MFLOPS | 10^6 |
| gigaFLOPS | GFLOPS | 10^9 |
| teraFLOPS | TFLOPS | 10^12 |
| petaFLOPS | PFLOPS | 10^15 |
| exaFLOPS | EFLOPS | 10^18 |
| zettaFLOPS | ZFLOPS | 10^21 |
| yottaFLOPS | YFLOPS | 10^24 |
Fully Connected Layer
-
LAYER = (INPUT NODES) * (OUTPUT NODES) + BIAS
where * is the dot product discussed previously.
-
So, For calculating FLOPs, we are just multiplying input and output. We can also add bias term, but for approximation we can leave it out.
def _linear_flops(module, inp, out):
mul = module.in_features
add = module.in_features - 1
total_ops = (mul + add) * out.numel()
return total_opsActivations
- Most of the activations don't come with any overhead of multiplication but they do have some simpler arithemetic operation to it.
RELU
- LAYER = INPUT NODES
# y = max(x,0)
def _relu_flops(module, inp, out):
return inp.numel()Tanh
- LAYER = INPUT NODES * 5
# y = e^(x) - e^(-x) / e^(x) + e^(-x)
def _tanh_flops(module, inp, out):
# exp, exp^-1, sub, add, div for each element
total_ops = 5 * inp.numel()
return total_opssigmoid
- LAYER = INPUT NODES * 4
# y = 1 / (1 + e^(-x))
def _sigmoid_flops(module, inp, out):
# negate, exp, add, div for each element
total_ops = 4 * inp.numel()
return total_opsPooling Layer
- Depends on type of Pooling and Stride
MaxPool 1D, 2D, 3D
- LAYER = Max(INPUT NODES)
# Same as output
def _maxpool_flops(module, inp, out):
total_ops = out.numel()
return total_opsAverage MaxPool 1D, 2D, 3D
- LAYER = Average(INPUT NODES)
# Same as output with kernel size
def _avgpool_flops(module, inp, out):
# pool: kernel size, avg: 1
kernel_ops = _torch.prod(_torch.Tensor([module.kernel_size]))
total_ops = (kernel_ops + 1) * out.numel()
return total_opsConvolutions
- LAYER = Number of Kernel x Kernel Shape x Output Shape
def _convNd_flops(module, inp, out):
kernel_ops = module.weight.size()[2:].numel() # k_h x k_w
bias_ops = 1 if module.bias is not None else 0
# (batch x out_c x out_h x out_w) x (in_c x k_h x k_w + bias)
total_ops = out.nelement() * \
(module.in_channels // module.groups * kernel_ops + bias_ops)
return total_opsDepthwise convolution
- Filter and input is broken channel-wise and convolved separately. After that, they are stacked together. Example
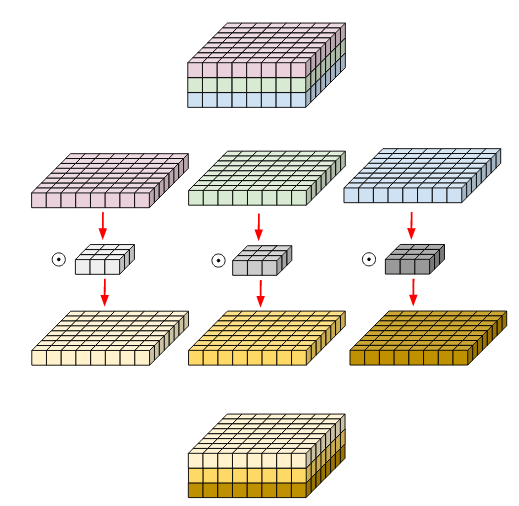{kind=link}
-
Number of operations are reduced here:
LAYER = Number of Kernel x Kernel Shape x Output Shape(without channel)
Pointwise convolution
-
1x1 Filter is applied on each pixel of input with same channel. Example
-
Number of operations are reduced here:
LAYER = Number of Kernel x Kernel Shape(1x1) x Output Shape(without channel)
{kind=link}